
Bitcoin and the Byzantine Generals Problem
In fault-tolerant computer systems, and in particular distributed computing systems, Byzantine fault tolerance is the characteristic of a system that tolerates the class of failures known as the Byzantine Generals' Problem, which is a generalized version of the Two Generals' Problem.
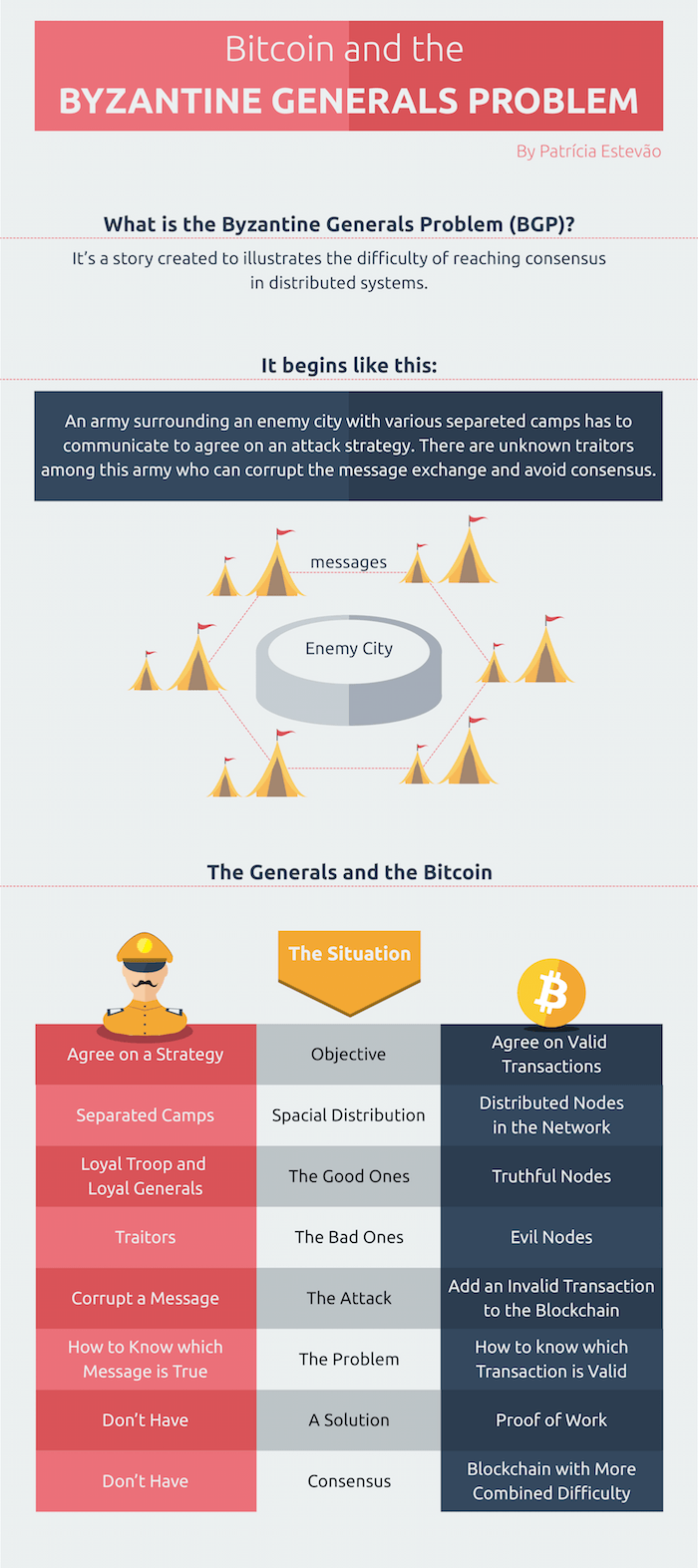 Visualize and Download High-Resolution Infographic
Visualize and Download High-Resolution InfographicThe phrases interactive consistency or source congruency have been used to refer to Byzantine fault tolerance, particularly among the members of some early implementation teams.
The objective of Byzantine fault tolerance is to be able to defend against Byzantine failures, in which components of a system fail with symptoms that prevent some components of the system from reaching agreement among themselves, where such agreement is needed for the correct operation of the system.
Correctly functioning components of a Byzantine fault tolerant system will be able to immutably provide the system's service assuming there are not too many faulty components.
The following practical, concise definitions are helpful in understanding Byzantine fault tolerance:
- Byzantine fault - Any fault presenting different symptoms to different observers
- Byzantine failure - The loss of a system service due to a Byzantine fault in systems that require consensus
The terms fault and failure are used here according to the standard definitions originally created by a joint committee on "Fundamental Concepts and Terminology" formed by the IEEE Computer Society's Technical Committee on Dependable Computing and Fault-Tolerance and IFIP Working Group 10.4 on Dependable Computing and Fault Tolerance.
Note that the type of system services which Byzantine faults affect are agreement (a.k.a consensus) services.
Origin
Byzantine refers to the Byzantine Generals' Problem, an agreement problem (described by Leslie Lamport, Robert Shostak and Marshall Pease in their 1982 paper, "The Byzantine Generals Problem") in which a group of generals, each commanding a portion of the Byzantine army, encircle a city.
These generals wish to formulate a plan for attacking the city. In its simplest form, the generals must only decide whether to attack or retreat. Some generals may prefer to attack, while others prefer to retreat. The important thing is that every general agrees on a common decision, for a halfhearted attack by a few generals would become a rout and be worse than a coordinated attack or a coordinated retreat.
The problem is complicated by the presence of traitorous generals who may not only cast a vote for a suboptimal strategy, they may do so selectively. For instance, if nine generals are voting, four of whom support attacking while four others are in favor of retreat, the ninth general may send a vote of retreat to those generals in favor of retreat, and a vote of attack to the rest.
Those who received a retreat vote from the ninth general will retreat, while the rest will attack (which may not go well for the attackers). The problem is complicated further by the generals being physically separated and must send their votes via messengers who may fail to deliver votes or may forge false votes.
Byzantine fault tolerance can be achieved if the loyal (non-faulty) generals have a unanimous agreement on their strategy. Note that there can be a default vote value given to missing messages. For example, missing messages can be given the value The typical mapping of this story on to computer systems is that the computers are the generals and their digital communication system links are the messengers.
Several examples of Byzantine failures that have occurred are given in two equivalent journal papers. These and other examples are described on the NASA DASHlink web pages. These web pages also describe some phenomenology that can cause Byzantine faults.
Byzantine errors were observed infrequently and at irregular points during endurance testing for the New Virginia Class submarine.
Several solutions were described by Lamport, Shostak, and Pease in 1982. They began by noting that the Generals' Problem can be reduced to solving a "Commander and Lieutenants" problem where Loyal Lieutenants must all act in unison and that their action must correspond to what the Commander ordered in the case that the Commander is Loyal.
One solution considers scenarios in which messages may be forged, but which will be Byzantine-fault-tolerant as long as the number of traitorous generals does not equal or exceed one third of the generals. The impossibility of dealing with one-third or more traitors ultimately reduces to proving that the one Commander and two Lieutenants problem cannot be solved, if the Commander is traitorous.
To see this, suppose we have a traitorous Commander A, and two Lieutenants, B and C: when A tells B to attack and C to retreat, and B and C send messages to each other, forwarding A's message, neither B nor C can figure out who is the traitor, since it is not necessarily A—another Commander could have forged the message purportedly from A.
It can be shown that if n is the number of generals in total, and t is the number of traitors in that n, then there are solutions to the problem only when n > 3t and the communication is synchronous (bounded delay).
A second solution requires unforgeable message signatures. For security-critical systems, digital signatures (in modern computer systems, this may be achieved in practice using public-key cryptography) can provide Byzantine fault tolerance in the presence of an arbitrary number of traitorous generals.
However, for safety-critical systems, simple error detecting codes, such as CRCs, provide the same or better coverage at a much lower cost. This is true for both Byzantine and non-Byzantine faults. Thus, cryptographic digital signature methods are not a good choice for safety-critical systems, unless there is also a specific security threat as well.
While error detecting codes, such as CRCs, are better than cryptographic techniques, neither provide adequate coverage for active electronics in safety-critical systems. This is illustrated by the Schrödinger CRC scenario where a CRC-protected message with a single Byzantine faulty bit presents different data to different observers and each observer sees a valid CRC.
Also presented is a variation on the first two solutions allowing Byzantine-fault-tolerant behavior in some situations where not all generals can communicate directly with each other.
Several system architectures were designed c. 1980 that implemented Byzantine fault tolerance. These include: Draper's FTMP, Honeywell's MMFCS, and SRI's SIFT.
In 1999, Miguel Castro and Barbara Liskov introduced the "Practical Byzantine Fault Tolerance" (PBFT) algorithm, which provides high-performance Byzantine state machine replication, processing thousands of requests per second with sub-millisecond increases in latency.
PBFT triggered a renaissance in Byzantine fault tolerant replication research, with protocols like Q/U, HQ, Zyzzyva, and ABsTRACTs working to lower costs and improve performance and protocols like Aardvark and RBFT working to improve robustness.
UpRight is an open source library for constructing services that tolerate both crashes ("up") and Byzantine behaviors ("right") that incorporates many of these protocols' innovations.
In addition to PBFT and Upright, there is the BFT-SMaRt library, a high-performance Byzantine fault-tolerant state machine replication library developed in Java. This library implements a protocol very similar to PBFT's, plus complementary protocols which offer state transfer and on-the-fly reconfiguration of hosts. BFT-SMaRt is the most recent effort to implement state machine replication, still being actively maintained.
Archistar utilizes a slim BFT layer for communication. It prototypes a secure multi-cloud storage system using Java licensed under LGPLv2. Focus lies on simplicity and readability, it aims to be the foundation for further research projects.
One example of BFT in use is Bitcoin, a peer-to-peer digital currency system. The Bitcoin network works in parallel to generate a chain of Hashcash style proof-of-work. The proof-of-work chain is the key to overcome Byzantine failures and to reach a coherent global view of the system state.
Some aircraft systems, such as the Boeing 777 Aircraft Information Management System (via its ARINC 659 SAFEbus® network), the Boeing 777 flight control system, and the Boeing 787 flight control systems, use Byzantine fault tolerance. Because these are real-time systems, their Byzantine fault tolerance solutions must have very low latency.
For example, SAFEbus can achieve Byzantine fault tolerance with on the order of a microsecond of added latency.
Some spacecraft such as the SpaceX Dragon flight system and the NASA Crew Exploration Vehicle consider Byzantine fault tolerance in their design.
Byzantine fault tolerance mechanisms use components that repeat an incoming message (or just its signature) to other recipients of that incoming message. All these mechanisms make the assumption that the act of repeating a message blocks the propagation of Byzantine symptoms.
For systems that have a high degree of safety or security criticality, these assumptions must be proven to be true to an acceptable level of fault coverage.
When providing proof through testing, one difficulty is creating a sufficiently wide range of signals with Byzantine symptoms. Such testing likely will require specialized fault injectors.
Known examples of Byzantine failures</h3
Early solutions
Practical Byzantine fault tolerance
Byzantine fault tolerance software
Byzantine fault tolerance in practice